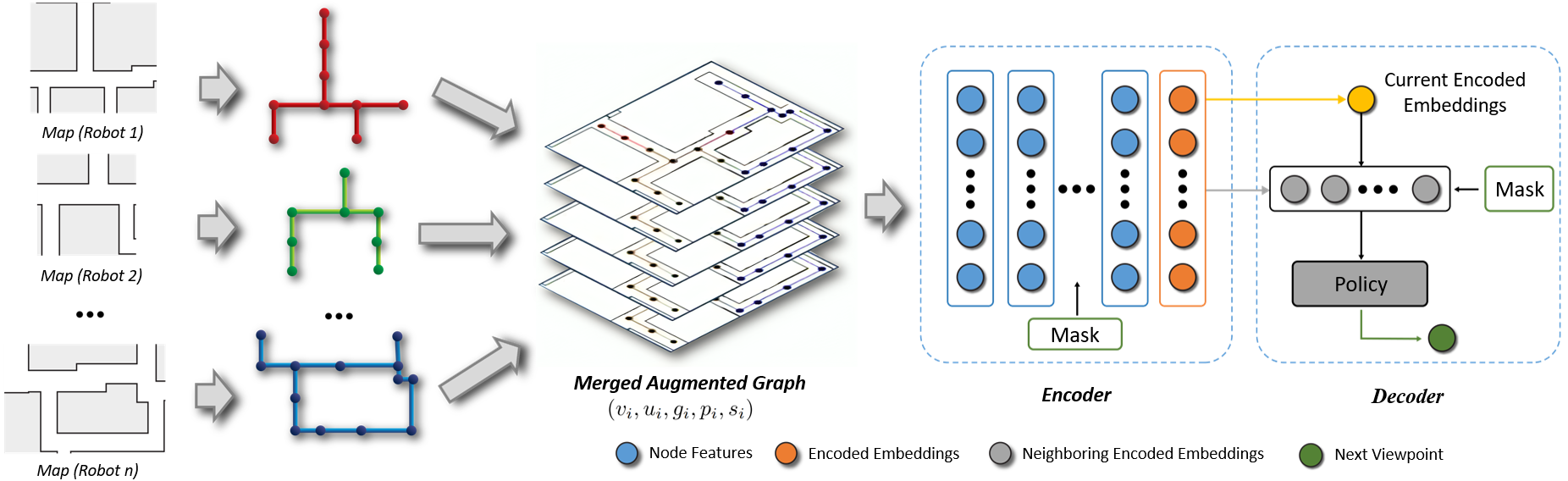
Approach
IR2 propose a novel information-sharing strategy that achieves high exploration efficiency by estimating the future impact of current exploration and rendezvous decisions. There are three key contributions to our proposed work: (1) We use an attention-based neural network trained by deep reinforcement learning (DRL) to help robots learn to sequence non-myopic decisions. (2) We implement two-stage curriculum learning, where robots are placed in increasingly difficult exploration environments with increasing frequency and duration of disconnectivity. This drives robots to learn complex, dynamic connectivity strategies to attain even higher exploration efficiency. (3) We utilize a hierarchical graph formulation, to enable scaling of our strategy to large-scale environments. This involves maintaining both a sparse global graph representation of the robots’ map and a dense local graph centered on the robot. Combining graphs at different spatial scales helps robots strike a balance between long- and short-term exploration and rendezvous goals.